Exporting INE Datasets
Sun Oct 20 2024A couple of weeks ago, my partner wanted to get some data from the official Spain statistics institute, INE (Instituto Nacional de Estadística de España). The process was not straightforward and I thought I could spend some time exploring how INE publishes its data and what are the best options to access it programmatically.
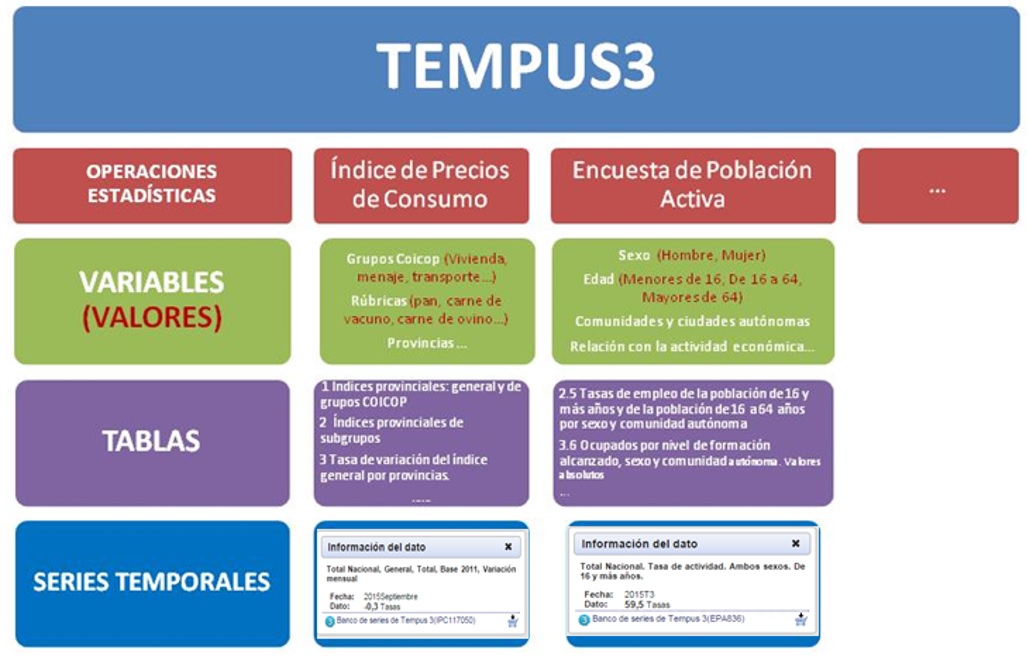
As expected, there is an official INE API, which relies on their own database, Tempus3. Sadly, as expected, it is not very well documented and it is not very easy to use.
Learnings
- Tempus3 is a “flexible” time series database. Also has several abstraction layers that make it easier to link data. It might be too flexible and that makes it hard to use and understand. Even for a data person.
- Using the official endpoints to get table data, like
DATOS_TABLA, is very slow. And you need to deal with paginations. - The INE is hosting all their tables as CSVs in a not so public endpoint (
https://www.ine.es/jaxiT3/dlgExport.htm?t=[TABLE_ID]). - CSVs are not compressed and some of them are very big (>50GB). Mostly because they have lots of string columns, repeating for each row.
- API endpoints might return 200 but the response is…
{"status" : "Petición en proceso. Actualice página pasados unos minutos."}. Helpful, but quite unique way to handle errors.
Exporting Data
With the information above, I started to tinker with different methods to export as many tables as possible and settled on the following approach.
You can list all available operations with OPERACIONES_DISPONIBLES, then list all available tables inside that operation with TABLAS_OPERACION to get all the table IDs! That means you can download all the tables in a given operation with a tool like aria2 in a fast and reliable way.
Doing that takes around 2 hours and will download around 200GB of CSVs. That’s a lot of data but… what happens if you transform these CSVs to a modern format like Parquet? Well… turns out you can reduce the datasets size to less than 500MB (zstd compression is amazing).
Since is not that much data, I decided to push the Parquet files to a Hugging Face INE Dataset and made a small file to serve as the index. This is it:
The INE datasets files are available under the tablas folder, alongside some of their metadata and a README with some information I was able to gather about the dataset.
This means you can query any dataset with DuckDB and thanks to the speed and compression of Parquet files, even from the browser.
Still need to refine the script a bit more and perhaps automate so the Hugging Face Dataset is always up to date. But found this was a great example of how modern data tooling can be used to make data more accessible, cheaper to access and easier to use.
You can check the code in the INE Data Exporter repository on GitHub!
Future Work
Right now, the code works well but it requires at least 300GB of disk space to run. This makes it hard to schedule on a GitHub Action. I’m looking into ways a workload like this could be run on a “serverless” platform for free. Tinkered a bit trying to make a cronjob inside a HuggingFace Spaces, but the disk space is still an issue there.
If you have any ideas, please let me know!
Check out the Part 2 blog post if you want to know more about the project.